La fragilidad del ecosistema digital y la necesidad de mirar atrás
El internet da una falsa sensación de permanencia. Pensamos que un servidor va a sostener un blog personal o el portal de noticias de una startup para siempre, pero la cruda realidad es que la vida útil media de una página web apenas roza los 100 días antes de cambiar drásticamente o desaparecer. ¿Por qué nos empeñamos en recuperar estos fragmentos de código del pasado?
El fenómeno del link rot y la evaporación de datos
Estamos lejos de eso que decían los optimistas sobre un almacenamiento infinito y eterno. El fenómeno conocido como degradación de enlaces destruye miles de referencias científicas, periodísticas y culturales cada jornada que pasa. Cuando una empresa quiebra o simplemente decide no renovar su dominio de 15 dólares al año, todo ese contenido se esfuma en el vacío digital. Y aquí es donde se complica la situación para los investigadores, ya que no basta con buscar en Google; el motor de búsqueda tradicional solo indexa lo que está vivo hoy, ignorando por completo el cadáver digital de lo que existió ayer.
La captura de pantalla como documento histórico y legal
Yo he visto casos donde un simple pantallazo guardado a tiempo ha decidido litigios de propiedad intelectual multimillonarios. Una captura estática o un volcado de código HTML antiguo no es mero entretenimiento nostálgico para nostálgicos de los años noventa. Seamos claros: estos registros sirven como pruebas notariales de qué se ofrecía, cómo funcionaba un diseño de interfaz en el año 2012 o qué promesas hacía una marca en su landing page original. La reconstrucción visual nos otorga una perspectiva limpia, libre del sesgo del rediseño moderno.
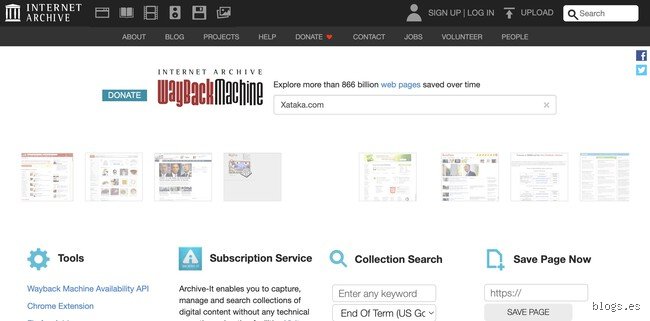
La Wayback Machine: El titán del archivo digital
Hablar de cómo ver capturas de pantalla de sitios web antiguos y no mencionar a la organización sin fines de lucro Internet Archive sería una absoluta falta de respeto profesional. Ubicada físicamente en una antigua iglesia de San Francisco, esta entidad lleva operando desde 1996 con un objetivo titánico: almacenar una copia de toda la cultura humana digitalizada.
El funcionamiento de los rastreadores automáticos y los bots
El sistema se apoya en programas autónomos llamados Wayback-SP, los cuales recorren la estructura de la red saltando de un hipervínculo a otro sin descanso. Pero el proceso no es perfecto (muchas veces los archivos multimedia pesados o los scripts complejos de JavaScript se rompen durante el guardado), lo que genera esas páginas a medio cargar tan comunes en los archivos. A pesar de estas imperfecciones de código, el motor ha logrado acumular más de 866 mil millones de páginas web guardadas hasta la fecha actual, una cifra que marea a cualquiera.
Aprende a navegar por el calendario de instantáneas
El uso de la herramienta es sumamente intuitivo si sabes interpretar su interfaz visual. Introduces la dirección URL exacta en el cuadro de búsqueda principal y el sistema te devuelve una línea temporal dividida por años. Al hacer clic en un año específico, aparece un calendario mensual repleto de círculos de colores —azules, verdes, inundando los días— que representan los momentos exactos en que el bot tomó la instantánea. Un círculo azul amplio significa que el rastreador web capturó la página con un código de respuesta 200 exitoso, garantizando que verás la web tal cual lucía en esa fecha concreta.
Alternativas especializadas y motores de búsqueda alternos
La sabiduría convencional dicta que si algo no está en el gran archivo de San Francisco, simplemente dejó de existir. Eso lo cambia todo cuando descubres que existen herramientas regionales y privadas que operan bajo lógicas completamente distintas y que a menudo guardan lo que otros descartan.
Archive.today: El especialista en la web dinámica moderna
Esta plataforma europea se ha convertido en la herramienta favorita de periodistas de investigación y analistas de datos por una razón muy particular. A diferencia del gran gigante americano, este servicio guarda un duplicado exacto del texto y de los elementos gráficos de manera estática, eliminando elementos activos peligrosos o scripts pesados que suelen romper las páginas viejas. Además, su capacidad para saltarse ciertos muros de pago debidos a suscripciones la convierte en una opción sumamente atractiva. ¿El único inconveniente real? Su índice de búsqueda es significativamente más pequeño y depende en gran medida de las peticiones manuales de los propios usuarios.
Comparativa técnica: Captura estática frente a rastreo completo
Al analizar las metodologías sobre cómo ver capturas de pantalla de sitios web antiguos, nos topamos con una división tecnológica fundamental que afecta directamente la calidad del material que vas a recuperar.
Archivos WARC frente a los simples archivos PNG
Un pantallazo tradicional en formato de imagen te muestra la superficie, el diseño visual básico, pero te deja completamente ciego respecto a lo que ocurría detrás del navegador. Por otro lado, el estándar técnico conocido como Web ARChive (WARC) reúne en un único archivo comprimido no solo las imágenes, sino también las hojas de estilo CSS, los archivos de traducción y las peticiones originales al servidor. Si estás buscando estudiar la evolución de la experiencia de usuario de las plataformas de comercio electrónico entre el año 2008 y el 2018, necesitas interactuar con archivos WARC vivos que te permitan clicar en los menús desplegables.
Errores comunes o ideas falsas al desenterrar el pasado digital
Existe una creencia ridícula y generalizada de que todo lo que se sube a Internet permanece allí de forma automática. El mito del almacenamiento infinito ha distorsionado nuestra percepción de la memoria digital. Pensar que basta con introducir una dirección URL para obtener al instante capturas de pantalla de sitios web antiguos con una fidelidad del cien por cien es un error ingenuo. Las herramientas de archivado no son cámaras fotográficas perfectas, sino sistemas automatizados que lidian a diario con servidores caídos y protocolos de exclusión de robots.
La trampa del archivo robots.txt
Mucha gente se frustra al buscar un portal del año 2005 y encontrar una pantalla en blanco con un código de error técnico. El problema es que los rastreadores respetan las directrices de los administradores originales. Si un webmaster decidió bloquear a los bots mediante un archivo de texto en la raíz de su servidor, esa información se perdió para siempre en el vacío digital. Y no importa que diez años después el dominio haya cambiado de dueño o esté completamente abandonado; el veto inicial genera un agujero negro histórico que ninguna tecnología pública puede reparar de forma retroactiva.
El mito de la interactividad total
¿Esperabas entrar en un foro antiguo y poder rellenar formularios o enviar mensajes? Seamos claros: estás contemplando un cadáver digital disecado. El intento de interactuar con bases de datos que dejaron de existir en la década pasada es el error más frecuente entre los usuarios inexpertos. Las copias almacenadas son réplicas estáticas de la interfaz visual, meros reflejos de código HTML y hojas de estilo CSS huérfanas de su motor trasero. Pero la nostalgia distorsiona la lógica y nos empuja a hacer clic en botones que ya no conducen a ninguna parte.
El truco del código fuente y los servidores DNS alternativos
Cuando las plataformas comerciales fallan y la desesperación aumenta, los profesionales de la investigación digital recurren a metodologías mucho más agresivas. La minería de datos profunda permite recuperar elementos visuales que los rastreadores estándar pasaron por alto debido a errores de renderizado. En lugar de limitarse a observar la superficie visual estropeada, el secreto radica en inspeccionar las tripas del documento técnico almacenado.
Extracción manual de rutas de imágenes
A veces la interfaz principal aparece rota porque las imágenes apuntaban a un subdominio que el motor de indexación no consideró relevante. Si modificas manualmente el código HTML descargado del archivo, puedes redirigir esas llamadas hacia servidores alternativos que aún conserven los activos originales. Y este proceso de costura digital es el que diferencia a un simple curioso de un verdadero analista web. Modificar los registros del sistema DNS local para engañar a tu propio navegador simulando que estás en el año 2008 te abrirá puertas que considerabas cerradas bajo siete llaves.
Preguntas Frecuentes sobre arqueología web
¿Es legal utilizar capturas de pantalla de sitios web antiguos con fines comerciales?
El vacío legal en este ámbito genera intensos debates jurídicos internacionales. Aunque las plataformas de almacenamiento actúan bajo el amparo de la preservación histórica sin ánimo de lucro, los derechos de propiedad intelectual del diseño original siguen perteneciendo a sus creadores durante un plazo que suele superar los 70 años tras su publicación. Si pretendes usar estas imágenes en un producto comercializado, te arriesgas a recibir una demanda por infracción de copyright, salvo que la empresa original haya sido liquidada legalmente y sus activos no hayan sido adquiridos por fondos de inversión. La jurisprudencia actual en el 90 por ciento de los países occidentales penaliza el uso no autorizado de marcas registradas visibles en copias históricas.
¿Por qué faltan tantos elementos gráficos en las interfaces antiguas?
Los navegadores modernos procesan la información de una forma radicalmente distinta a los programas de 1999. El descarte sistemático de las tecnologías obsoletas como Adobe Flash Player o Microsoft Silverlight impide la visualización correcta de los elementos dinámicos que dominaban la red hace dos décadas. Las estadísticas indican que cerca del 45 por ciento de los portales creados durante el cambio de milenio dependían de complementos externos que hoy en día están bloqueados por motivos estrictos de ciberseguridad. Porque la prioridad de los desarrolladores actuales es proteger tu equipo informático, no facilitar tus viajes nostálgicos al pasado.
¿Existen alternativas privadas si los buscadores públicos no tienen registros?
Las agencias de inteligencia y las grandes corporaciones tecnológicas mantienen sus propios servidores de respaldo con fines de análisis competitivo y seguridad nacional. Compañías especializadas en analítica de datos poseen registros históricos que abarcan más de 12 petabytes de información estructurada que jamás ha sido expuesta al público general. El acceso a estas bases de datos exclusivas suele requerir suscripciones corporativas que superan los 500 dólares mensuales, limitando este recurso a bufetes de abogados o investigadores de mercado de alto nivel. Ninguna entidad privada te regalará sus archivos históricos de forma altruista si puede rentabilizarlos en el mercado de la ciberseguridad corporativa.
El destino inevitable de una memoria digital fragmentada
La obsesión contemporánea por registrar cada fragmento de información nos ha convertido en una civilización con una capacidad de almacenamiento colosal, pero con una fragilidad histórica preocupante. Depender exclusivamente de un puñado de organizaciones sin ánimo de lucro para salvaguardar la evolución de nuestro conocimiento digital es una irresponsabilidad colectiva monumental. Visualizar capturas de pantalla de sitios web antiguos debería entenderse como una actividad de preservación cultural prioritaria, no como un pasatiempo nostálgico dominical para informáticos aburridos. Las interfaces de la red reflejan los cambios políticos, sociales y económicos de nuestra era con una precisión que ningún libro de historia impreso podrá emular jamás. Si permitimos que las corporaciones destruyan sus antiguos portales bajo el pretexto de la optimización de servidores, estaremos consintiendo la quema de la biblioteca de Alejandría de nuestro tiempo. La memoria no puede ser un lujo privatizado supeditado a las fluctuaciones del mercado tecnológico o al capricho de los administradores de sistemas.